


BiFuG2-Spark: Bi-directional Fuzzy Granular-Cabin Parallel Attribute Reduction Accelerator with Granular-Group Collaboration
Hengrong Ju*, Tingting Shan, Weiping Ding*, Keyu Liu, Muhammad Jabir Khan, Jiashuang Huang, Xibei Yang
MOTIVATION
Ø Owing to the rapid advancement of Internet technology and the widespread adoption of intelligent devices, the explosive growth and accumulation of massive amounts of data have led to a reduction in data-processing effectiveness. In addition, owing to the volume and variety of big data, it is difficult to achieve an in-depth understanding and accurate analysis of the data.
Ø Many researchers have focused on researching attribute reduction accelerators to deal with the challenges proposed by big data. From the existing research results, the acceleration strategies are often in dependent, and few studies consider combining two or more strategies. Although these accelerators do not need to scan the whole sample, which reduces the computation of inter-sample distances, cases of repeated distance computation remain, which consumes a large amount of time.
Ø The traditional granular-cabin utilizes two virtual samples to construct the neighborhood space and uses it to construct information granules. Such a two-step strategy still consumes a lot of time. Traditional attribute reduction methods traverse the entire set of attributes for each evaluation, and only one best attribute can be selected for each traversal.
INNOVATION
Ø This paper constructs a new model that utilizes three virtual samples as well as a flexible sample radius to construct the granularity space. The model in this paper considers only a few samples in the bi-directional fuzzy granular-cabin when deriving the fuzzy information granules, without considering the whole dataset. This scheme greatly compresses the fuzzy neighborhood search space.
Ø The traditional rough set model has high computational complexity and can only be used to deal with data with discrete attributes. In this paper, the proposed bi-directional fuzzy granular-cabin is used as the basic unit to describe the fuzzy upper and lower approximation, which is an innovation to the existing rough approximation model based on fuzzy information granules.
Ø A granular group collaboration strategy is proposed for attribute reduction, in which the concept of attribute groups is fused with the proposed granular-cabin. In this approach, the original attributes are divided into different groups, reducing the time consumption for obtaining the reduction in each training set.
Ø The Spark platform utilizes memory computing technology to store the computed data in memory and realize distributed parallel acceleration, which greatly accelerates the processing speed. The attributes of the ranked reduction results are evaluated again on the master-node to improve the classification accuracy of the reduction.
METHOD
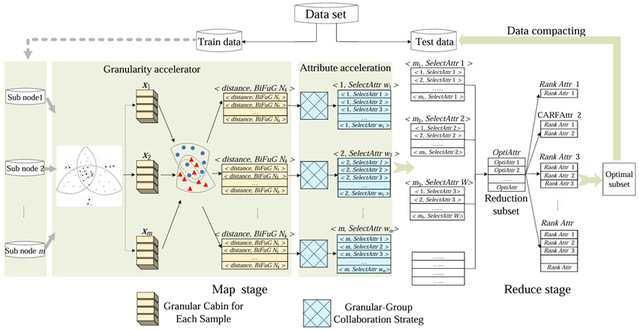
Fig. 1 presents the framework of this work. This paper proposes a Bi-directional Fuzzy Granular-cabin parallel attribute reduction accelerator method with Granular-group collaboration (BiFuG2-Spark) from the perspectives of samples, attributes, granularity, and platforms. This method divides the dataset into smaller subsets and distributes them to multiple compute sub-nodes for parallel processing. A bi-directional fuzzy granular-cabin model is constructed with three virtual samples, and a granular-group collaboration strategy is introduced to accelerate the reduction process. The reductions of each sub-node are finally aggregated on a master-node, and the effective attribute subset can be achieved.
Ø Distributed parallel: The purpose is to gradually reduce the size of the fuzzy granular-cabin by selecting a subset of samples much smaller than the dataset, very close to the actual fuzzy information granules. Acceleration in the information granule is achieved without changing the results of the selected attributes.
Ø Bi-directional fuzzy granular-cabin: The purpose is to gradually reduce the size of the fuzzy granular-cabin by selecting a subset of samples much smaller than the dataset, very close to the actual fuzzy information granules. Acceleration in the information granule is achieved without changing the results of the selected attributes.
Ø Granular-group collaboration: Spark core contains the most basic and core functionality, built on a unified elastic distributed dataset RDD. An RDD is a collection of distributed objects, divided into multiple partitions, with each partition representing a subset of the data. Different partitions, which are different subsets of the data, can be saved to different nodes in the cluster for parallel computing.
EXPERIMENTAL RESULTS
TABLE Ⅰ RUN TIME OF CONSTRUCTION GRANULARITY (UNIT:S)
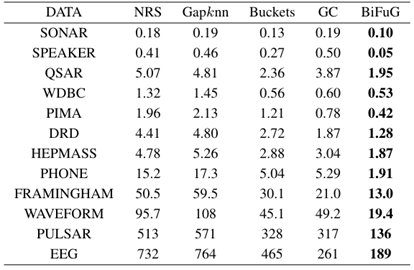
TABLE ⅠⅠ THE RUNNING TIME OF THE ATTRIBUTE REDUCTION (UNIT:S)
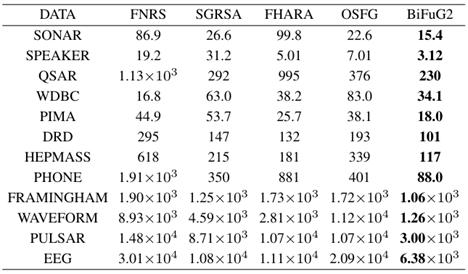
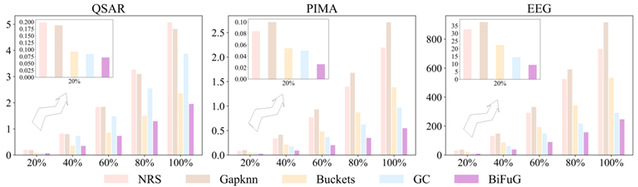
Fig. 2. Run time of construction granularity as data sample increases.
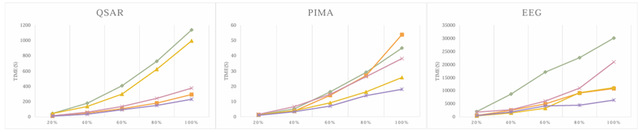
Fig. 3. Run time of attribute reduction with the increases of data.

(a) SVM (b) KNN (c) RF
Fig. 4. CD diagrams comparing the classification accuracy of different algorithms: (a)SVM, (b)KNN, (c)RF classifier.

Fig. 5. Run time and speed ratio under different partitions.
Link: https://ieeexplore.ieee.org/document/10506638


